Answering while Summarizing Multi-task Learning for Multi-hop QA with Evidence Extraction
Answering while Summarizing: Multi-task Learning for Multi-hop QA with Evidence Extraction
任务
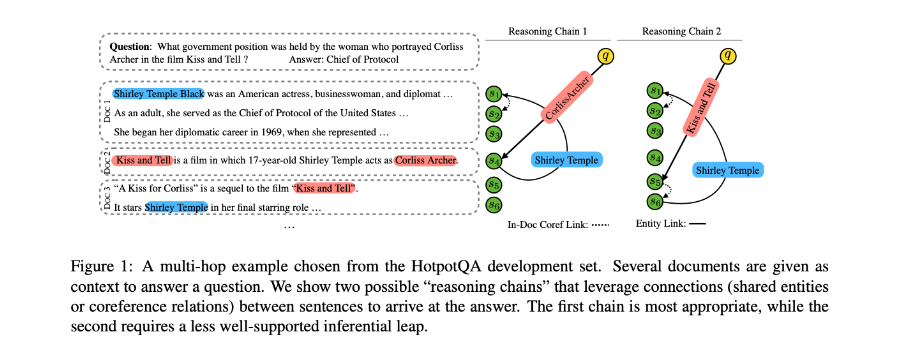
本文聚焦于可解释的多跳QA任务,要求系统通过推理和收集参考文本的不相交片段来返回带有证据句子的答案。提出了Query Focused Extractor(QFE)模型用于证据提取,并使用多任务学习与QA模型。
方法(模型)
Query Focused Extractor (QFE)
整体模型采用多任务学习,答案选择采用QA模型,证据提取采用QFE模型。
QFE的灵感来自于提取式摘要模型(extractive summarization models),将可解释的多跳QA的证据提取看作是一个以查询为中心的摘要任务,与现有方法独立提取每个证据句相比,它通过使用RNN对问题句的关注机制(attention mechanism),依次提取证据句。它使QFE考虑到证据句之间的依赖性,覆盖了问题句中的重要信息。
模型结构
除了evidence layer其他部分和HotpotQA的baseline模型一样。
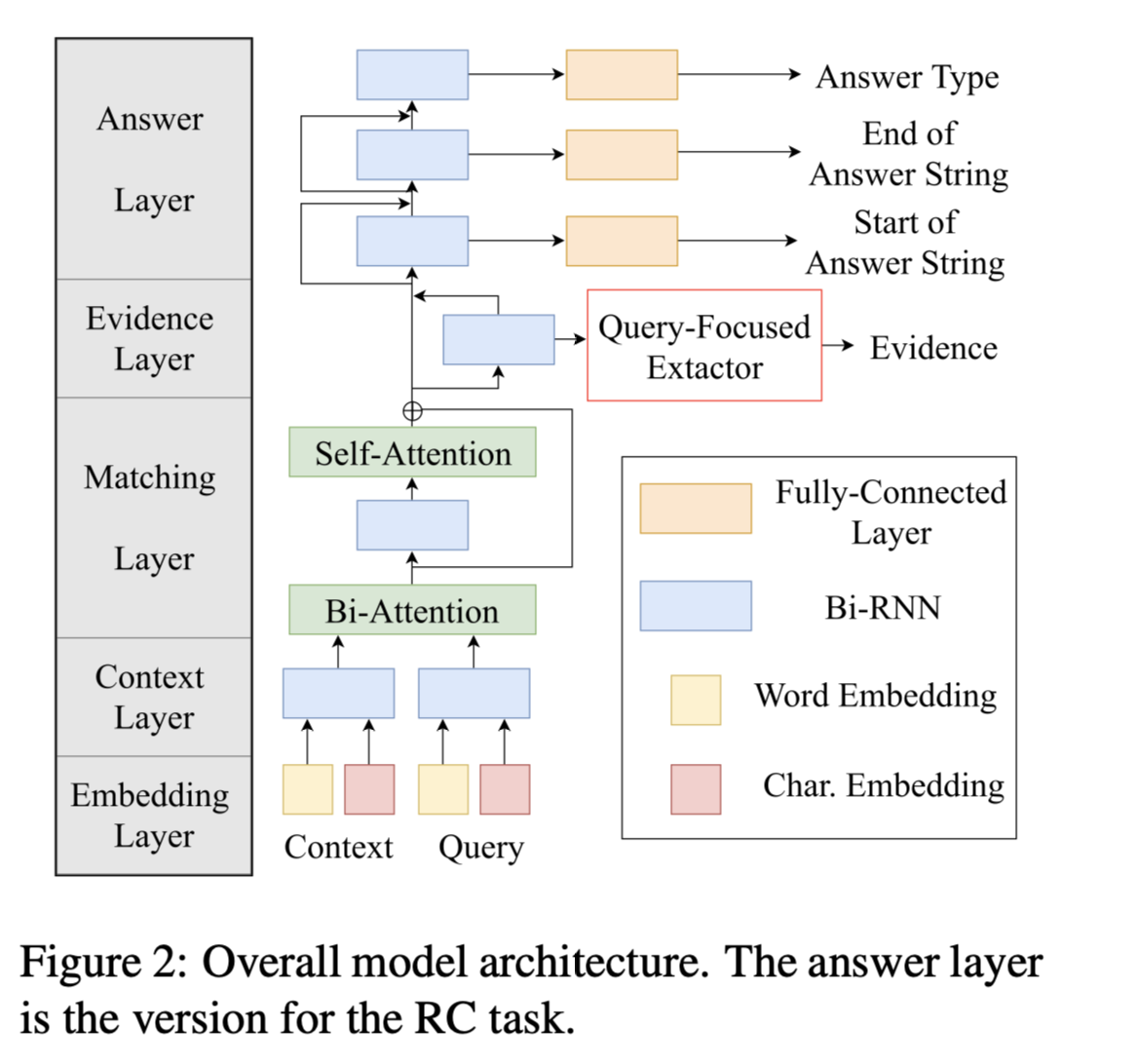
Input: Context C (multiple texts), Query Q (text)
The Word Embedding Layer
将C和Q编码为词向量(word vectors)序列。
output: $C_1, Q_1$
The Context Layer
encodes $C_1, Q_1$as contextual vectors $C_2, Q_2$ by using a bi-directional RNN(Bi-RNN).
output: $C_2, Q_2$
The Matching Layer
encodes $C_2, Q_2$as matching vectors $C_3$ by using bi-directional attention,a Bi-RNN, and selfattention.
The Evidence Layer
first encodes $C_3$ as $[\overrightarrow{C4};\overleftarrow{C4}]$ by a Bi-RNN.
设$j_1(i)$为C中第i句的第一个词的索引,$j_2(i)$为最后一个词的索引。
QFE输出第i句为证据的概率分布:
X:句子级上下文向量
Y:上下文查询向量Q2
证据层将单词级向量和句子级向量连接起来。
The Answer Layer
predicts the answer type $A_T$ and the answer string $A_S$ from $C_5$.
Answer Layer有多个堆叠的Bi-RNN。每个Bi-RNN的输出被全连接层和softmax函数映射到概率分布上。
Query Focused Extractor
QFE结构:

input:
X:句子级上下文向量
Y:上下文查询向量
将timestep定义为提取句子的操作。
RNN状态更新:
$e^t∈ {1, · · · , l_s}$ is the index of the sentence extracted at step t
$E^t= {e^1, · · · , e^t}$ to be the set of sentences extracted until step t
QFE根据概率分布提取第i个句子:
QFE选择$e^t$:
RNN的初始状态是通过全连接层和X的最大池获得的向量。
数据集
HotpotQA

性能水平
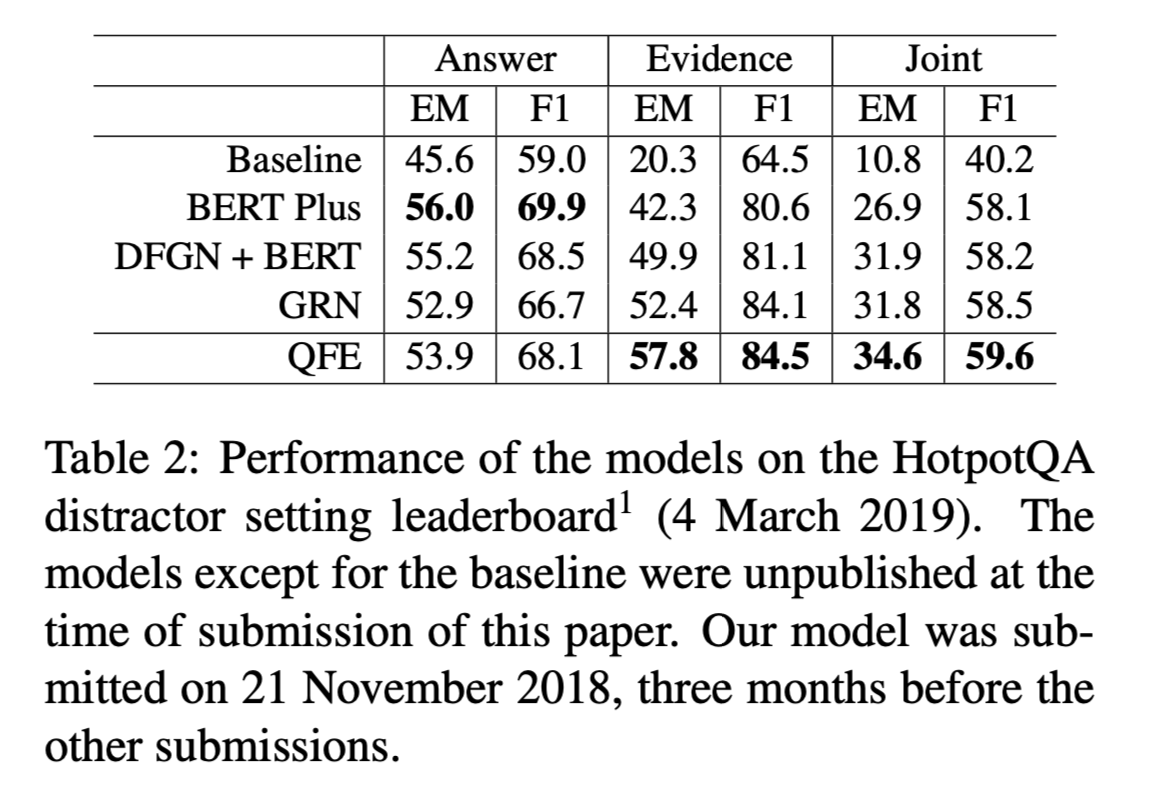
- 在distractor setting下,QFE证据提取得分方面表现最好。在joint EM and F1 metrics上取得了最先进的性能。QFE在所有指标上都优于基线模型的表现。
- QFE没有使用预训练模型,但在Evidence的评测下性能要比比DFGN + BERT 和 BERT Plus出色。
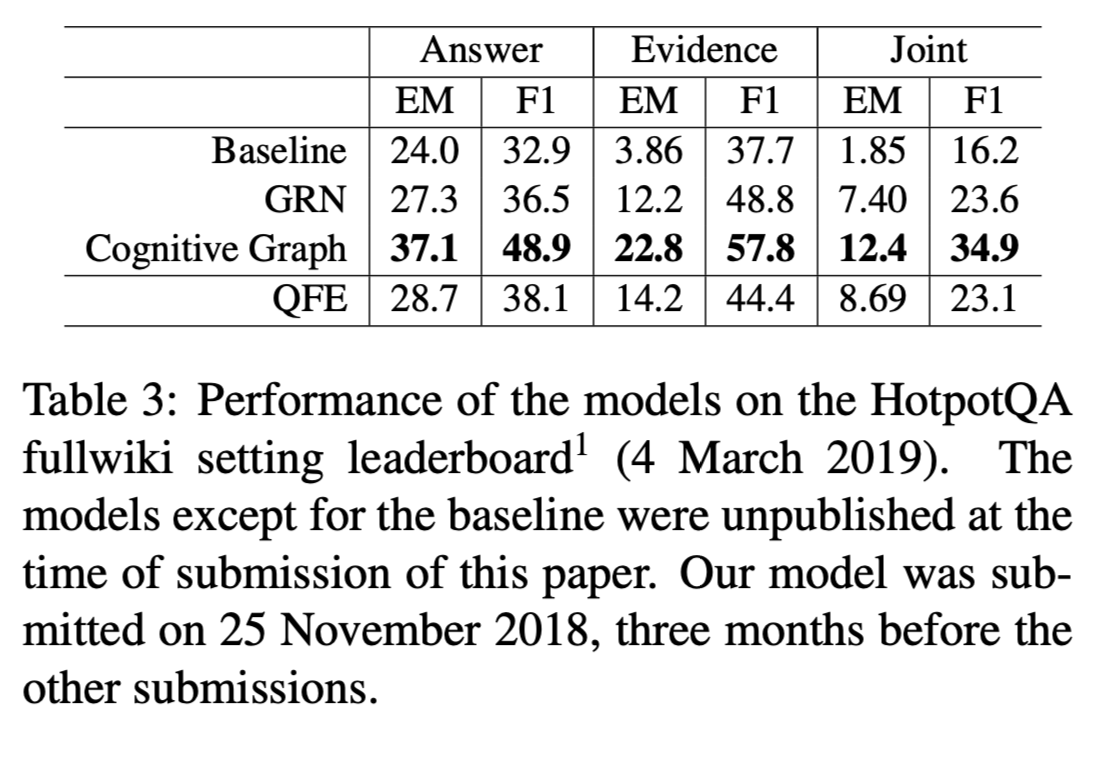
- 在fullwiki setting下,QFE性能优于baseline模型。
- 因为fullwiki的gold evidence sentences可能会少于两个甚至无法回答,出现数据集移位的问题导致性能未超越Cognitive Graph。
结论
消融实验
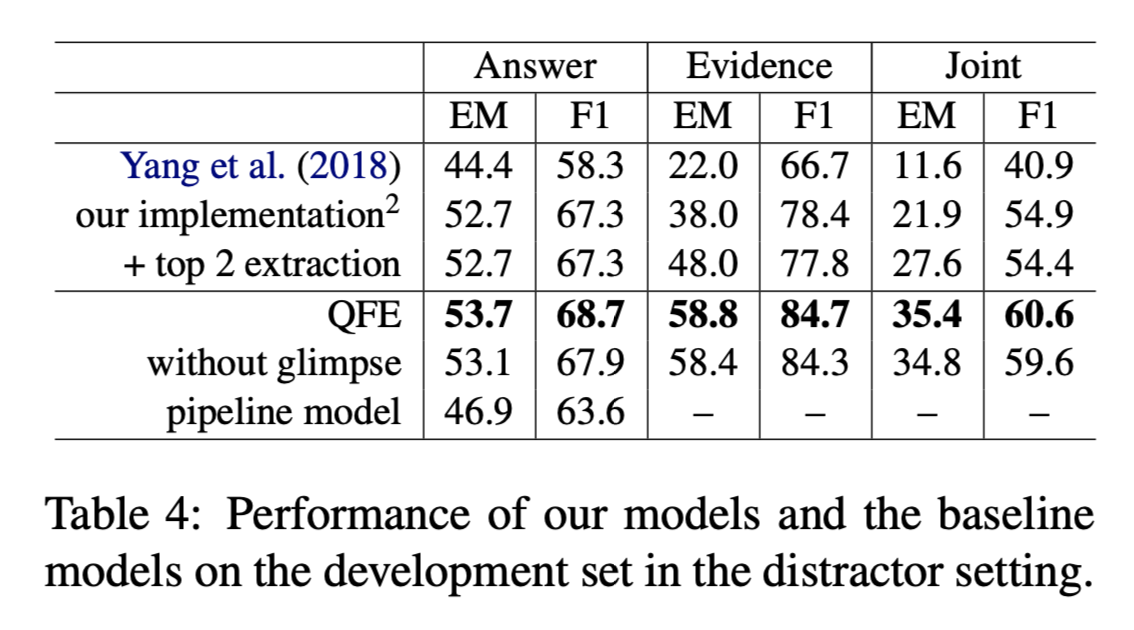
- evidence extraction model对证据提取和答案提取有效。
- 到达EOE句子自适应终止提取,对模型效果有所提升。
实验结果表明,采用简单RC基线模型的QFE在HotpotQA上实现了最先进的证据提取得分。虽然是为RC设计的,但在FEVER上也取得了最先进的证据提取成绩。(FEVER是一个在大型文本数据库上识别文本的任务),QFE替代证据提取模块可提高性能,自适应终止提取有助于确切匹配和证据提取的精确度,QFE问题的难度取决于所需证据句子的数量。