Multi-hop Question Answering via Reasoning Chains
Multi-hop Question Answering via Reasoning Chains
论文:2019-Multi-hop Question Answering via Reasoning Chains
基于推理链的多跳问题回答
任务
本文提出了一种在文本中提取离散推理链的方法,模型不依赖于gold annotated chains or “supporting facts,使用基于命名实体识别和共指消解的启发式算法得到的pseudogold reasoning chains。
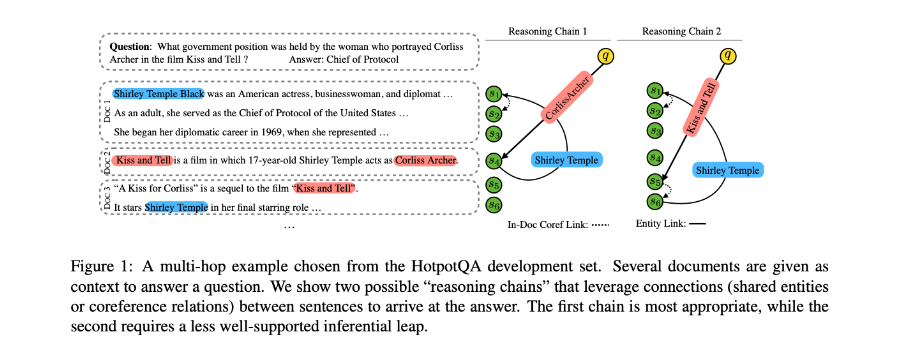
推理链是一系列的句子,逻辑上把问题与一个事实联系起来,这个事实与给出一个合理的答案相关(或部分相关)。
方法(模型)
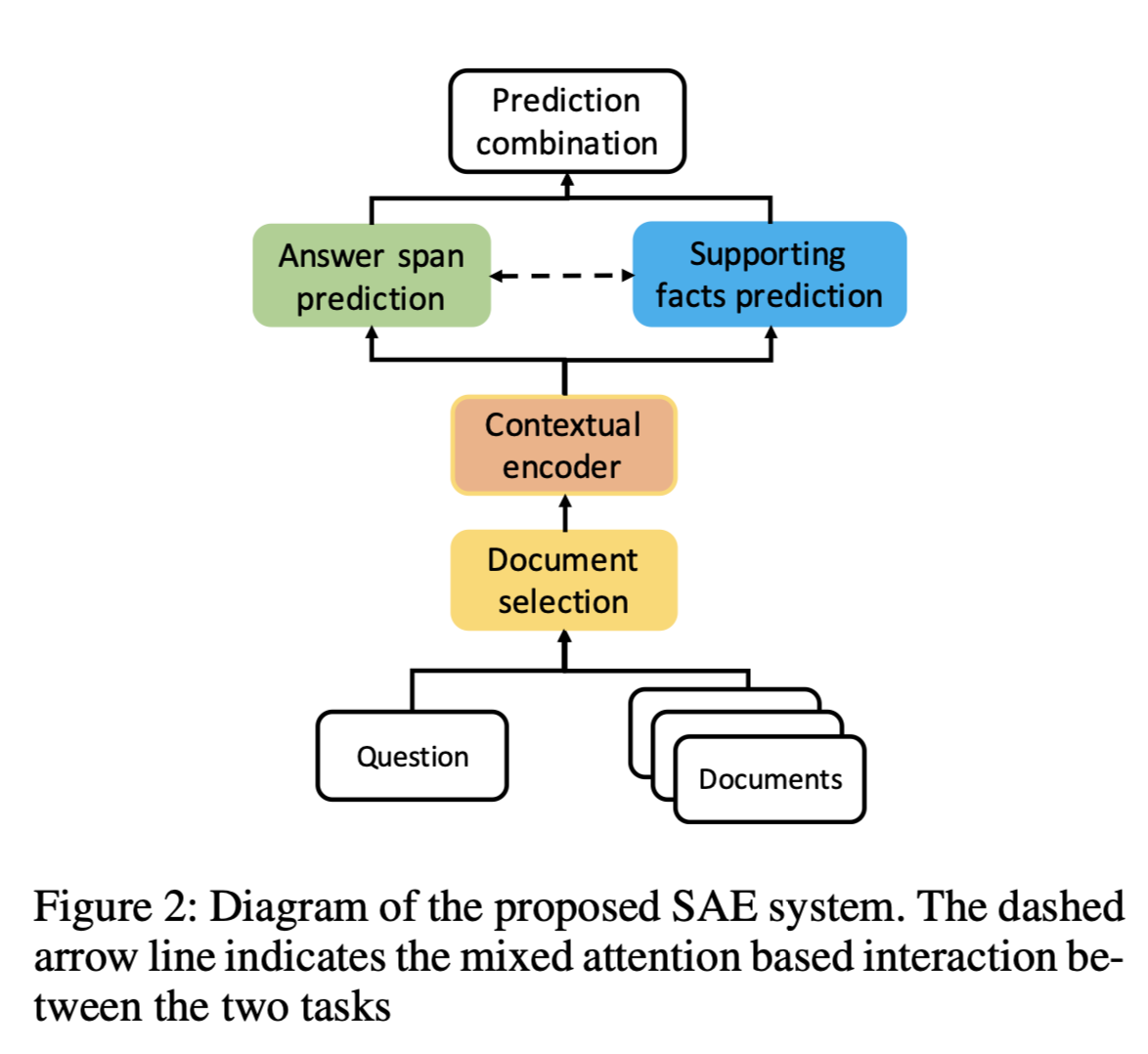
提出一个two-stage model
extractor model:提取推理路径。extractor模型对句子序列进行评分,并通过beam search生成n-best链列表。
answer module:将提取的推理链输入到BERT中提取最终的答案。
Learning to Extract Chains
Heuristic oracle chain construction
使用命名实体识别提取句子中的实体,如果两个句子中有匹配的实体,则在这两个节点上添加一条边。对段落中的所有句子进行这一操作。
从问题的节点开始,搜索所有可能的推理链。
使用两种方式选择heuristic oracles:
Shortest Path:选择最短的推理链。
Question Overlap:计算每条链的Rouge-F1,选择得分最高的推理链,这样可以找到更完整的答案链。
Chain extraction model
输入:文档+问题
处理流程:sentence encoding and chain prediction
Sentence Encoding
- 将输入问题和段落使用BERT编码。句子可以从段落中提取出来。
$s_j$表示段落$p_i$中第i句话
BERT-para
本文设计的paragraph-factored model,比在整个上下文运行BERT更高的效率和可拓展性。
使用bert-base-uncased预训练模型。
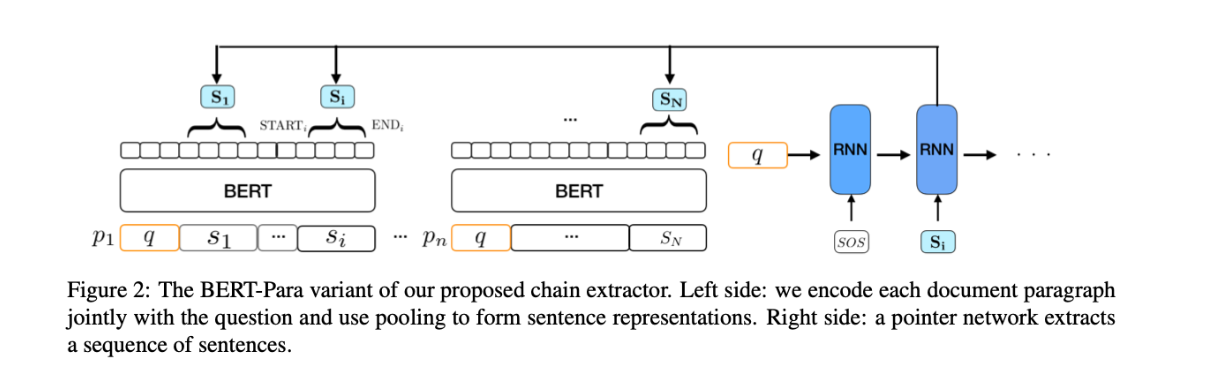
Chain Prediction
将所有编码的句子表示作为一个句子包,并采用基于LSTM的pointer network来提取推理链。
在第一步中,使用问题q的max-pooled表示初始化pointer network中的隐藏状态$h_0$,并提供一个特殊的令牌SOS作为第一个输入。
$c1, . . . , c{t−1}$:推理链中句子索引。
W:要学习的权重。
Training the Chain Extractor
step t的损失:
$c^∗_1$:目标句子
数据集
- WikiHop
- HotpotQA
性能水平&结论
Comparison of Chain Extraction Methods
- 使用更多的上下文有助于链提取器找到相关的句子。
- one-best推理连通常包含答案。
- Q-Overlap有助于找到更多的支持事实。
- 可以通过跨多个链使用并集来提高性能。(BRRT-Para(top5))

Results compared to other systems
HotpotQA:使用RoBERTa 预模型作为权重。
- 性能超过了使用标记支持事实的模型,说明本文提出的heuristicallyextracted chains可以有效的替代标记支持事实进行监督。

Evaluation of chains
有序抽取优于无序抽取。
在HotpotQA-Hard上,更需要多跳推理。

- 链接提取的性能已接近HotpotQA上的性能极限。
- Table4中人类评估的得分与模型在oracle上的F1的分相近,表明本文提出的模型不再需要人工注释的支持事实。