
GRAPH-BASED RECURRENT RETRIEVER
GRAPH-BASED RECURRENT RETRIEVER
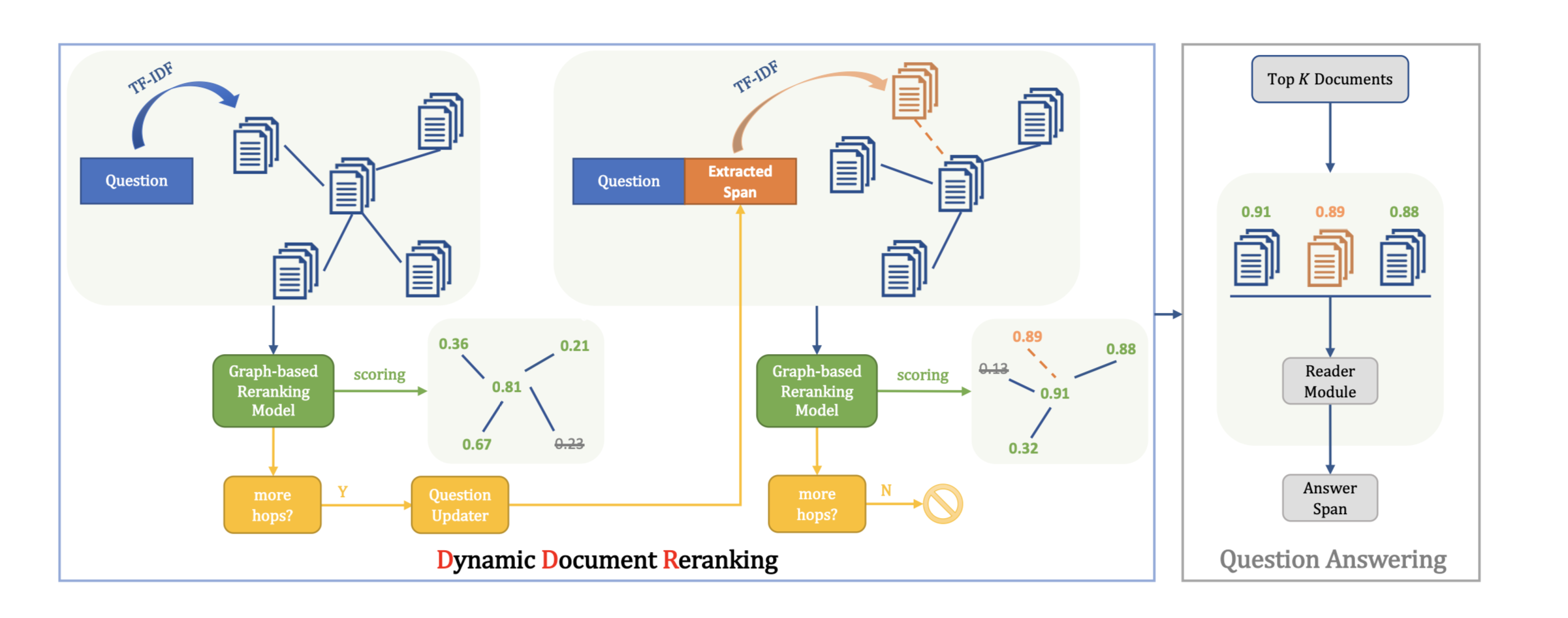
a new graph-based recurrent retrieval method
查找证据文档作为回答复杂问题的推理路径。
b:偏置项
- 使用RNN建模问题$Q$的推理路径。
- 给定问题$q$,在时间步$t$时,模型从候选段落集$C_t$中找出$p_i$ ,与$q$拼接计算$p_i$的概率。
- 遇到$[EOE]$时结束推理,允许它在给定每个问题的情况下捕获具有任意长度的推理路径。
本文BERT结构:

RNN结构:
$P(p_i|h_t)$:表示在时间步$t$选择段落$p_i$的概率。

最终得到推理路径【$p_1,p_2$】
beam search
- 通过束搜索得到给定时间步长的有限数量的最可能推理路径,减小输入BERT的数据量,减小计算量。
- $C_1$是用在输入问题上 TF-IDF 得分最高的段落。
- $C_t$是在C_1基础上,拓展的连接段落,用输入到BERT。
- 推理路径$E = [pi, . . . , p_k]$乘段落概率$P(p_i|h_1) . . . P(p_k|h{|E|})$得到beam search 的输出,即得到top B 推理路径 $E = {E_1, . . . , E_B}$作为BERT输入,再将BERT输出作为RNN输入。
BERT相关
Bidirectional Encoder Representations from Transformers
是Google以无监督的方式利用大量无标注文本训练的的语言代表模型,其架构为Transformer中的Encoder。
- 使用BERT预训练模型
bert-base-uncased不区分大小写。
BERT 里5个特殊tokens:
- [CLS]:在做分类任务时其最后一层的repr. 会被视为整个输入序列的repr。
repr指的都是一个可以用来代表某词汇(在某个语境下)的多维连续向量(continuous vector)。
- [SEP]:有两个句子的文本会被串接成一个输入序列,并在两句之间插入这个token 以做区隔。
- [UNK]:没出现在BERT 字典里头的字会被这个token 取代。
- [PAD]:zero padding 遮罩,将长度不一的输入序列补齐方便做batch 运算。
- [MASK]:未知遮罩,仅在预训练阶段会用到。
代码实现
加载BERT预训练模型
1 | model = BertForGraphRetriever.from_pretrained(args.bert_model,cache_dir=PYTORCH_PRETRAINED_BERT_CACHE / 'distributed_{}'.format(-1),graph_retriever_config=graph_retriever_config) |
默认从缓存中加载,下载之后源码中替换自己本地路径即可。
- any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
使用BertAdam自定义Adam优化器
1 | optimizer = BertAdam(optimizer_grouped_parameters, |
在前10%的steps中,lr从0线性增加到 init_learning_rate,这个阶段又叫 warmup,然后,lr又从 init_learning_rate 线性衰减到0(完成所有steps)。
对问题和段落加上[CLS],[SEP]
1 | def tokenize_question(question, tokenizer): |
RNN初始化
1 | self.rw = nn.Linear(2 * config.hidden_size, config.hidden_size) |
通过beam search 找出top B 推理路径
1 | b = 0 |
实验
下载程序:
1 | !git clone https://github.com/AkariAsai/learning_to_retrieve_reasoning_paths.git |
下载数据集
1 | %cd /content/learning_to_retrieve_reasoning_paths |
训练模型
1 | %cd /content/learning_to_retrieve_reasoning_paths/graph_retriever |
1 | !python3 run_graph_retriever.py \ |
—max_para_num:与问题相关的段落数量。如果—max_para_num是n,问题的基础真实段落数量是k(2),那么有n-2个段落作为训练的反例。此时反例数量为8。
—neg_chunk:为了控制GPU内存消耗,将负例拆分为小块。
- —max_select_num:指定模型推理步骤的最大数量,如果问题的基础真实段落数量是k,这个值应该为k+1,1表示结束符号EOE,此时k+1=3。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 没有胡子的猫Asimok!
相关推荐




评论

