SRLGRN
SRLGRN
论文:EMNLP2020-Semantic Role Labeling Graph Reasoning Network
语义角色标注图推理网络
任务
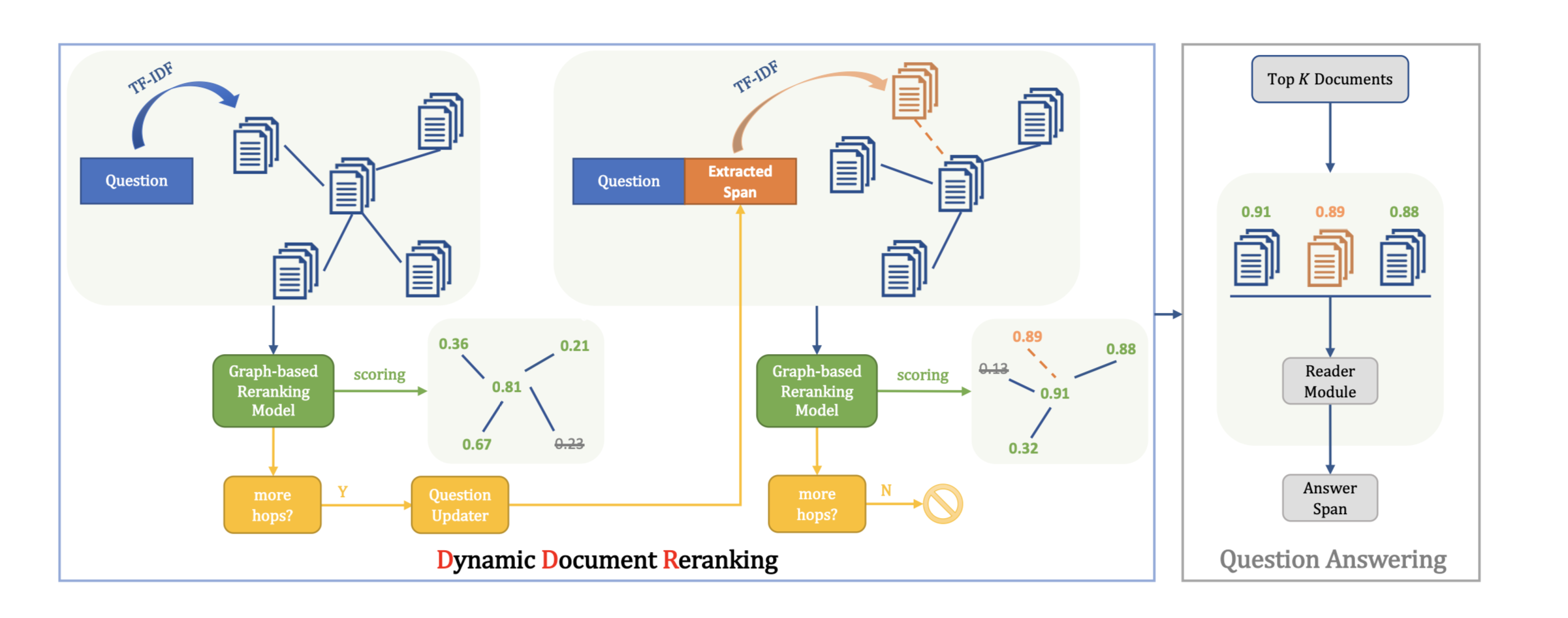
提出了一个基于句子语义结构的图推理网络来学习跨段落推理路径,并联合寻找支持事实和答案。
方法(模型)
SRLGRN
该框架在构建推理图网络时会考虑句子的语义结构。 不仅利用节点的语义角色,而且会利用边缘的语义。
训练一个段落选择模块来检索gold documents并最小化干扰因素。
构建了一个异类文档级图,其中包含以句子为节点以及SRL子图,其中SRL子图包括语义角色标签参数作为节点,谓词作为边。
训练图编码器来获得图节点表示,该图节点表示在学习的表示中结合了参数类型和谓词边的语义。
最后,共同训练一个multi-hop supporting fact prediction module和answer prediction module。
multi-hop supporting fact prediction module可以找到跨段落推理路径,answer prediction module可以得到最终答案。
based on contextual semantics graph representations as well as token-level BERT pre-trained representations.
模型结构:
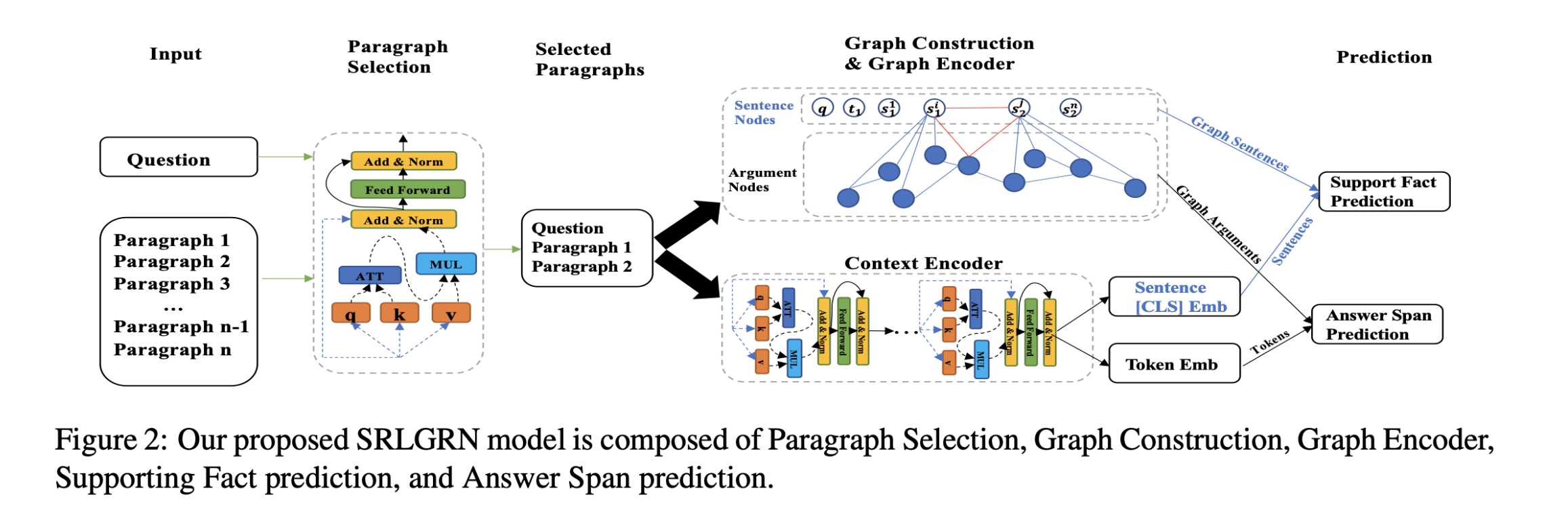
SRLGRN由段落选择,图形构造,图形编码器,支持事实预测和答案跨度预测模块组成。
Paragraph Selection
- based on the pre-trained BERT model
两轮解释:
First Round Paragraph Selection
input:$Q_1$
q: question
C: paragraph content
t: title
$s_n$: sentences
- 将$Q_1$输入到预训练的BERT编码器以获得token表示。
- 使用$BERT_{[CLS]}$作为该段的摘要表示。
- 利用两层MLP输出相关性得分。
- 选择获得最高相关性得分的段落作为第一相关上下文。
- 将$q$连接到所选段落作为$q_{new}$,以进行下一轮段落选择。
Second Round Paragraph Selection
- 对于剩余的N-1个候选段落,使用与第一轮段落选择相同的模型来生成相关性得分,该相关性得分以$q_{new}$和段落内容为输入。
- 将问题和两个选定的段落连接起来,形成一个新的上下文,用作图形构造的输入文本。
Heterogeneous SRL Graph Construction
每个数据实例构建一个包含document-level子图$S$和argument- predicate SRL 子图$Arg$的异构图。
- $S$
includes question q, title $t_1$and sentences $s_1^{1,…,n}$ from first round se- lected paragraph.and title $t_2$and sentences $s_2^{1,…,n}$ from the second round selected paragraph.
- $Arg$
包含使用AllenNLP-SRL模型生成的参数作为节点,谓词作为边。

异构图的边添加规则:
- 如果在该句子中有一个argument,则该句子和argument之间将存在一条边(图3中的黑色虚线)
- $s_i$和$s$两个句子,如果他们通过精确匹配共享一个参数,则存在一条边(红色虚线)
- 两个argument节点$Arg_i$ 和$Arg_j$之间存在谓词,则存在一条边(黑色实线)
- 如果它们共享一个argument,则问题和句子之间会有一条边(红色虚线)
建立了一个基于谓词的语义边缘矩阵$K$和一个异构边缘权重矩阵$A$。
语义边缘矩阵$K$是一个存储谓词单词索引的矩阵。
异构边缘权重矩阵$A$是存储不同类型边权重的矩阵。
Supporting Fact Prediction

- $G_S$: graph sentence embedding(蓝色圆圈)。
- BERT’s [CLS] token representation: 橙色圆圈。
- $X_S^{cand}$: 候选句子。
- $S_{cand}$:候选句子的相邻句子。
数据集
HotpotQA
性能水平

EM:完全匹配
F1:部分匹配
在Distractor setting下的测试结果:
该模型在Joint上获得了39.41%的完全精确匹配分数和66.37%的部分匹配分数,远超基线模型,相比其他模型也有明显的提升。这得益于token-level BERT和graph-level SRL node的结合。
结论
Ablation study

Graph:
删除整个SRL图。
与完整的SRLGRN模型相比,在F1评分上下降了8.46%。 如果删除SRL图,而仅使用BERT进行答案预测,则该模型将失去用于多跳推理的连接。
从SRL图中删除了基于谓词的边缘信息。
如果不合并语义边缘信息和参数类型,则答案跨度预测的F1分数降低2.9%。删除谓词边和参数类型将破坏SRL图中的参数-谓词关系,并打破推理链。
Joint:
如果不共同训练模型,性能将下降4.56%。
Language Models:
尽管BERT获得了相对更好的性能,但ALBERT架构的参数少18X,并且比BERT更快。
拓展
语义角色标注 (Semantic Role Labeling, SRL) 是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元 (语义角色) ,如施事、受事、时间和地点等。其能够对问答系统、信息抽取和机器翻译等应用产生推动作用。