Is Graph Structure Necessary for Multi-hop Question Answering?
Is Graph Structure Necessary for Multi-hop Question Answering?
论文:EMNLP 2020-Is Graph Structure Necessary for Multi-hop Question Answering
任务
探讨多步推理问答任务中是否需要图结构的问题。
验证自注意力或者Transformer可能更加擅长处理多步推理问答任务。
方法(模型)
- 本文的实验使用Distractor设定。
基线模型
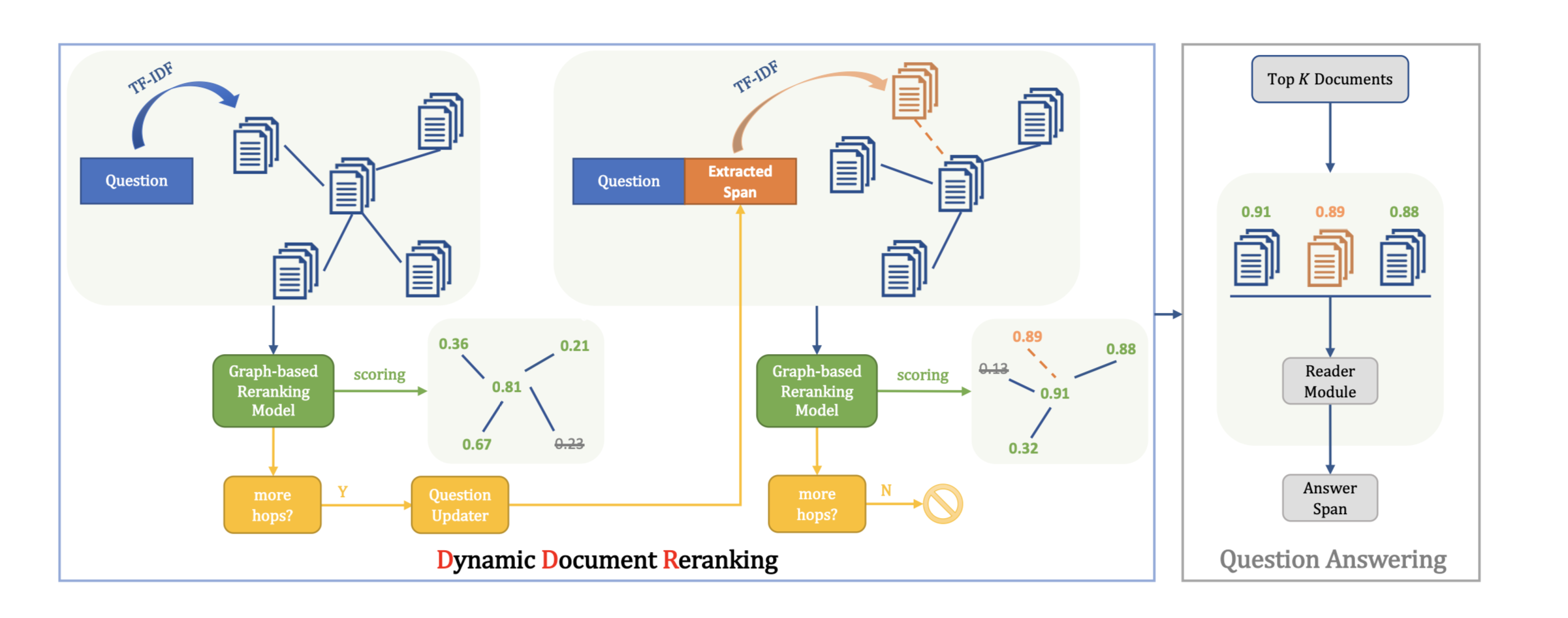
使用一个检索模型检出候选段落中的相关段落并输入一个基于图的问答模型,其中图中的所有节点都是由一个额外的NER模型所识别得到的实体构成。
使用一个RoBERTa large模型来计算每个问题与候选段落之间的相关性。
- 在编码层,将问题和上下文拼接并输入另一个RoBERTa large模型,所得到的输出被输入到一个双向注意力层来得到编码层的输出。
- 在图融合层(Graph Fusion Block),给定第$t-1$步的上下文表示$C{t-1}$,其中所有token的向量表示都会通过mean-max池化层来得到实体图中的所有节点的表示$H{t-1}\in ℝ^{2d\times N}$,其中N为实体的数量。
- 在预测层,这里使用了一种“瀑布式”的结构来预测HotpotQA任务所要求的答案文本和线索句子。
- 为了寻找文本中的实体并构建实体图,使用一个基于BERT的NER模型并在CoNLL’03数据集上进行微调。
理解图网络
原始文本中的实体被建模为实体图并使用图注意力网络进行处理,当实体图为全连接时,图注意力层将退化为传统的自注意力层。

为了回答一个需要多步推理的问题,首先需要从原始文本中找到与问题中出现的相同实体,然后以该实体作为起点构建从该实体到其他共现或相同实体的推理链。
实验
预训练模型使用Feature-based的方法。
包含图结构的模型
验证作为先验知识的邻接矩阵是否必要。
验证作为先验知识的邻接矩阵是否必要。
评估了不同邻接矩阵密度对于结果的影响。
将一个0-1矩阵的密度定义为其中1的比例。
不包含图的模型
为了验证图结构本身是否有必要,这里直接将两层的图结构替换为传统的Transformer层。其中编码层得到的上下文token表示直接输入Transformer。
数据集
HotpotQA数据集
- 一个广泛使用的多步推理问答数据。
- 该数据包含两种设定:Distractor,Fullwiki。
- Distractor设定中每个问题对应2个正确段落和8个干扰段落。
- Fullwiki设定则要求模型从整个维基百科中检出正确的段落。
性能水平
基线模型
- 基线模型在HotpotQA测试集的结果

本文提出的模型,在HotpotQA隐藏的测试集上与其他模型相比效果最优化。
- 不同设定下图结构的消融实验
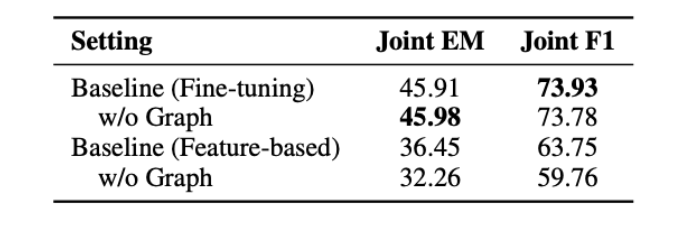
为了分析图结构对于整个模型起了多大的贡献,本文的模型移除了整个图融合模块,使预训练的输出直接输入给预测层。
在预训练模型以fine-tuning的方式使用时:
- 包含和不包含图结构的模型都取得了相似的结果。
当固定预训练模型的参数时:
- 包含图结构时:EM和F1显著下降。
- 移除图结构时:EM和F1略有下降。
理解图网络
设置不同模块条件下EM和F1性能的比较:

- 与基线模型相比,带有图融合层的模型有非常显著的优势。
- 给基线模型添加了图注意力层后,基线模型获得了较为明显的提升,但与添加自注意力机制的效果接近。
- Transformer也表现出了较好的推理能力。
位于不同分位点样本的邻接矩阵密度:

不同邻接矩阵密度下图注意力和自注意力的效果对比:

- 图注意力网络与自注意力在不同邻接矩阵密度的样本上结果相近,证明自注意力确实能够自行学会忽略不相干实体。
- 密度越大的样本EM/F1得分越高,这可能是因为这些样本长度普遍更短,因此也更加容易定位答案的位置。
结论
- 只有当预训练模型以Feature-based的方式使用时,图结构才会起到比较明显的作用。而当预训练模型以Fine-tuning的方式使用时,图结构并没有对结果起到贡献,因此,图结构可能不是解决多步推理问题所必要的结构。
- 图注意力机制和图结构可以被自注意力机制或Transformer代替。